Gallery
The images below show some of the results of my daily basis work. This process includes data exploration, pattern identification, network analysis or prediction, informed decision analysis and functional exploration of the results.
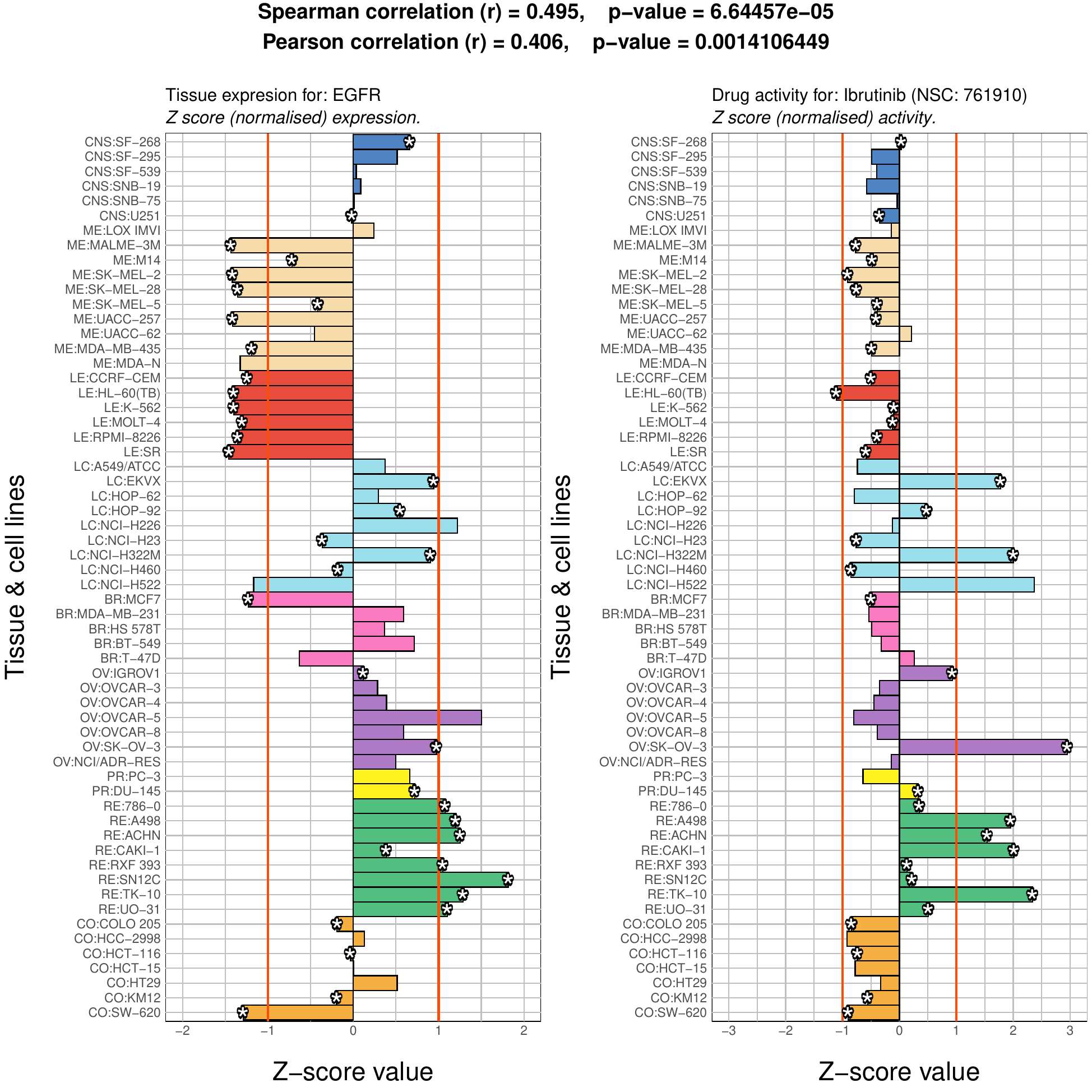
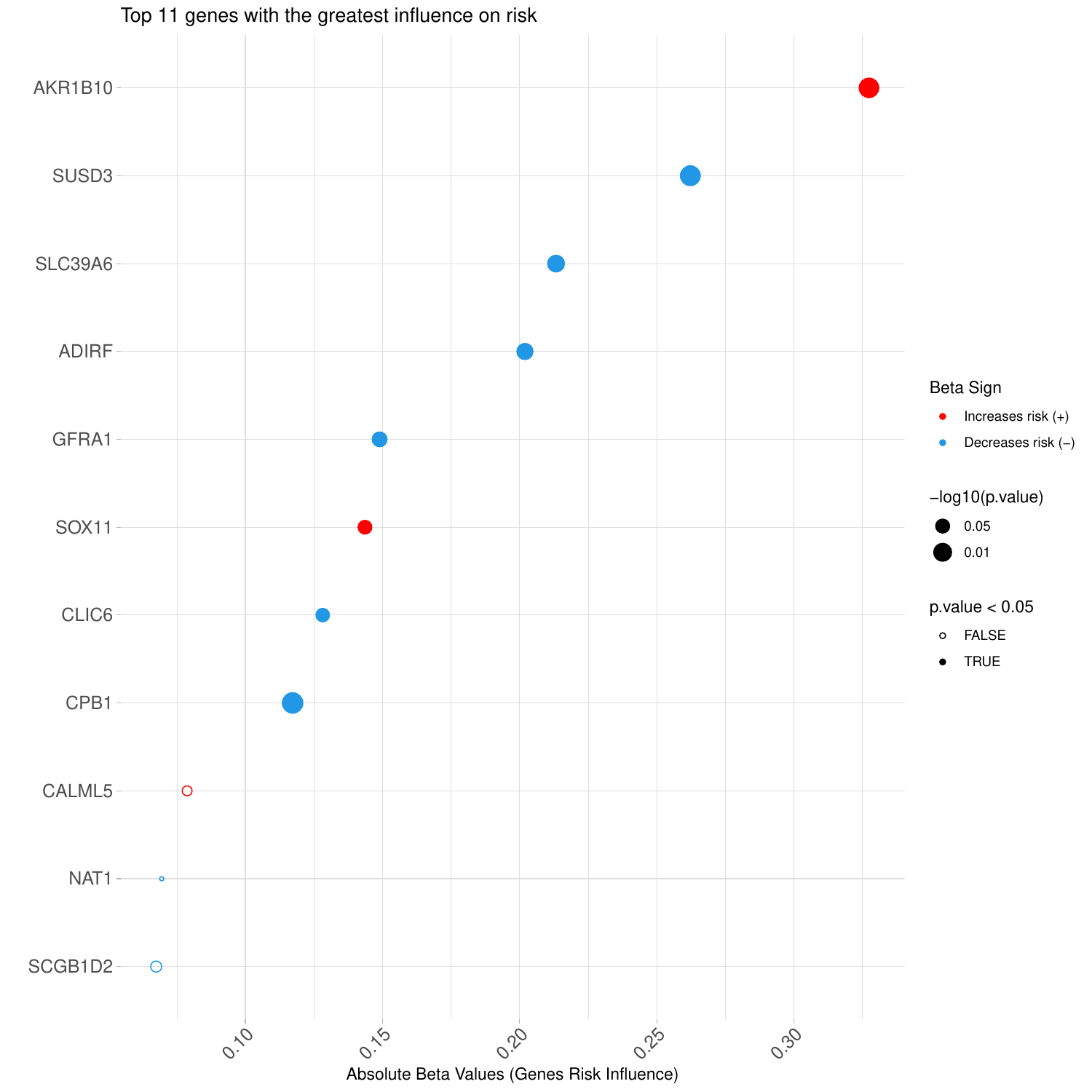
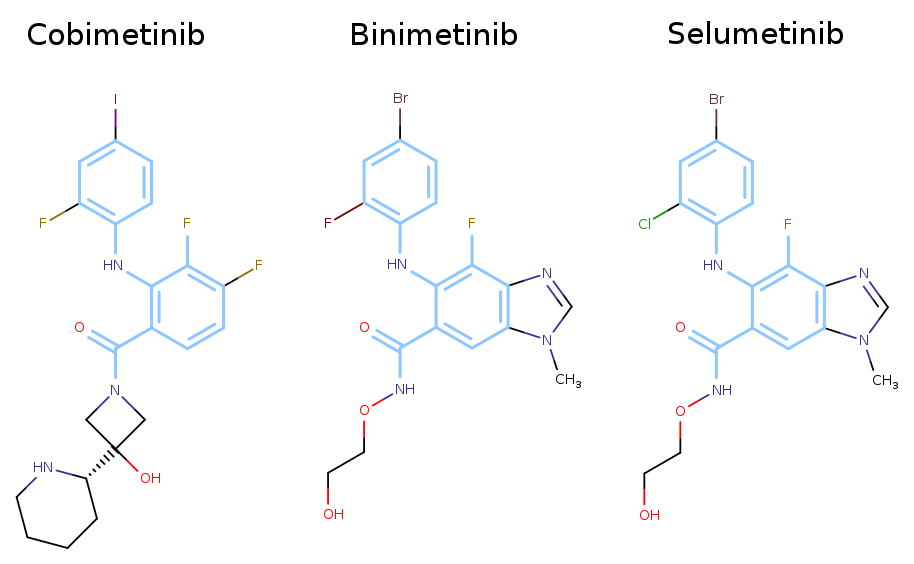
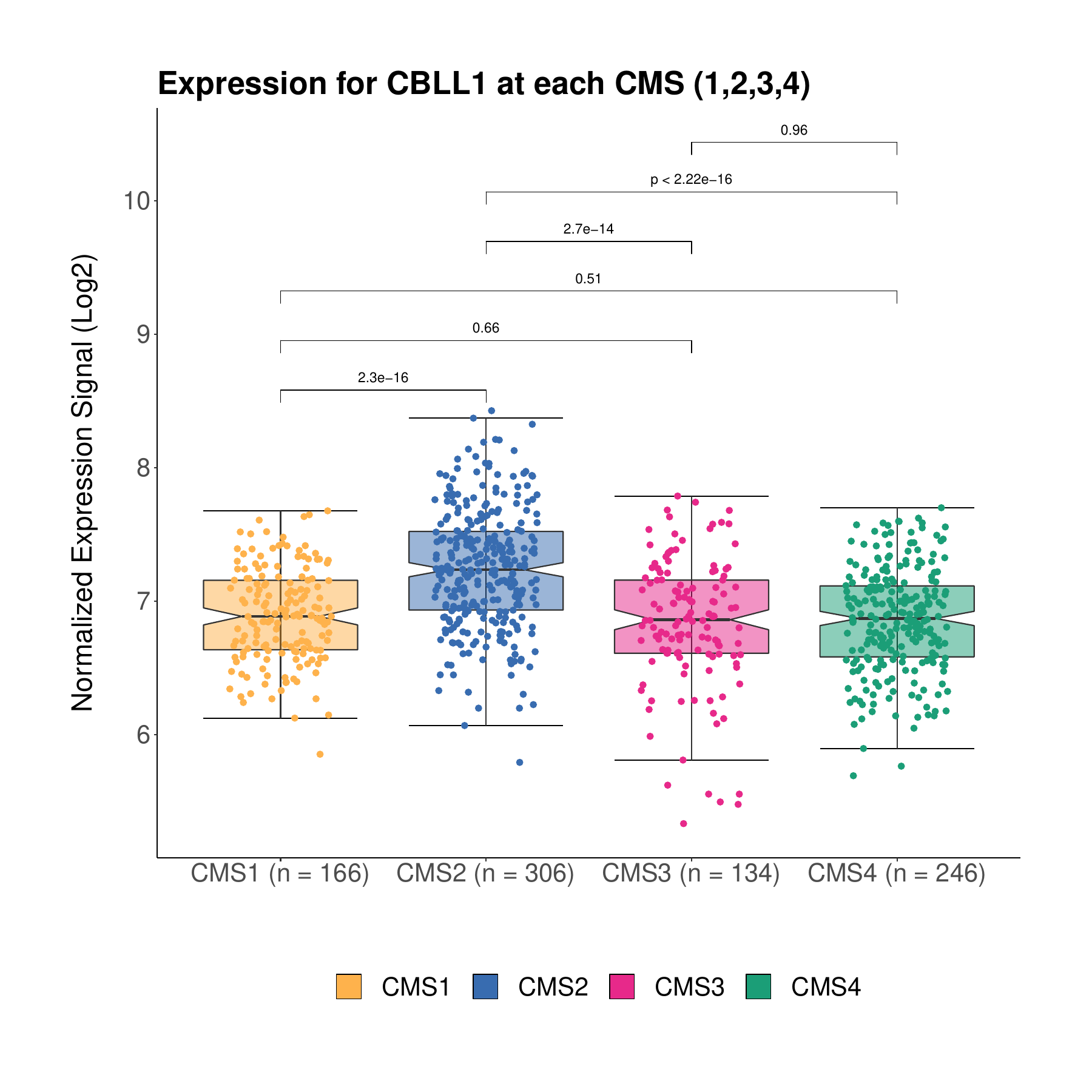
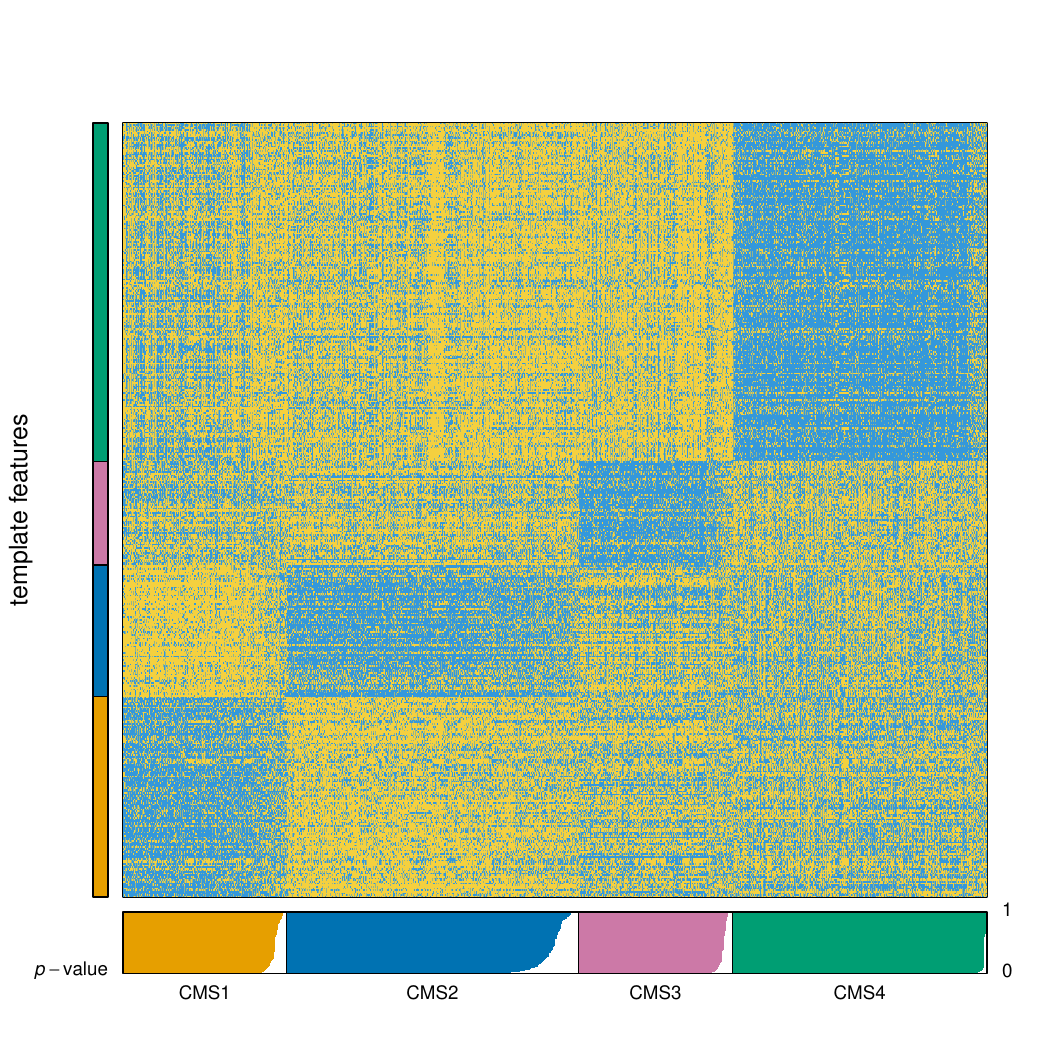
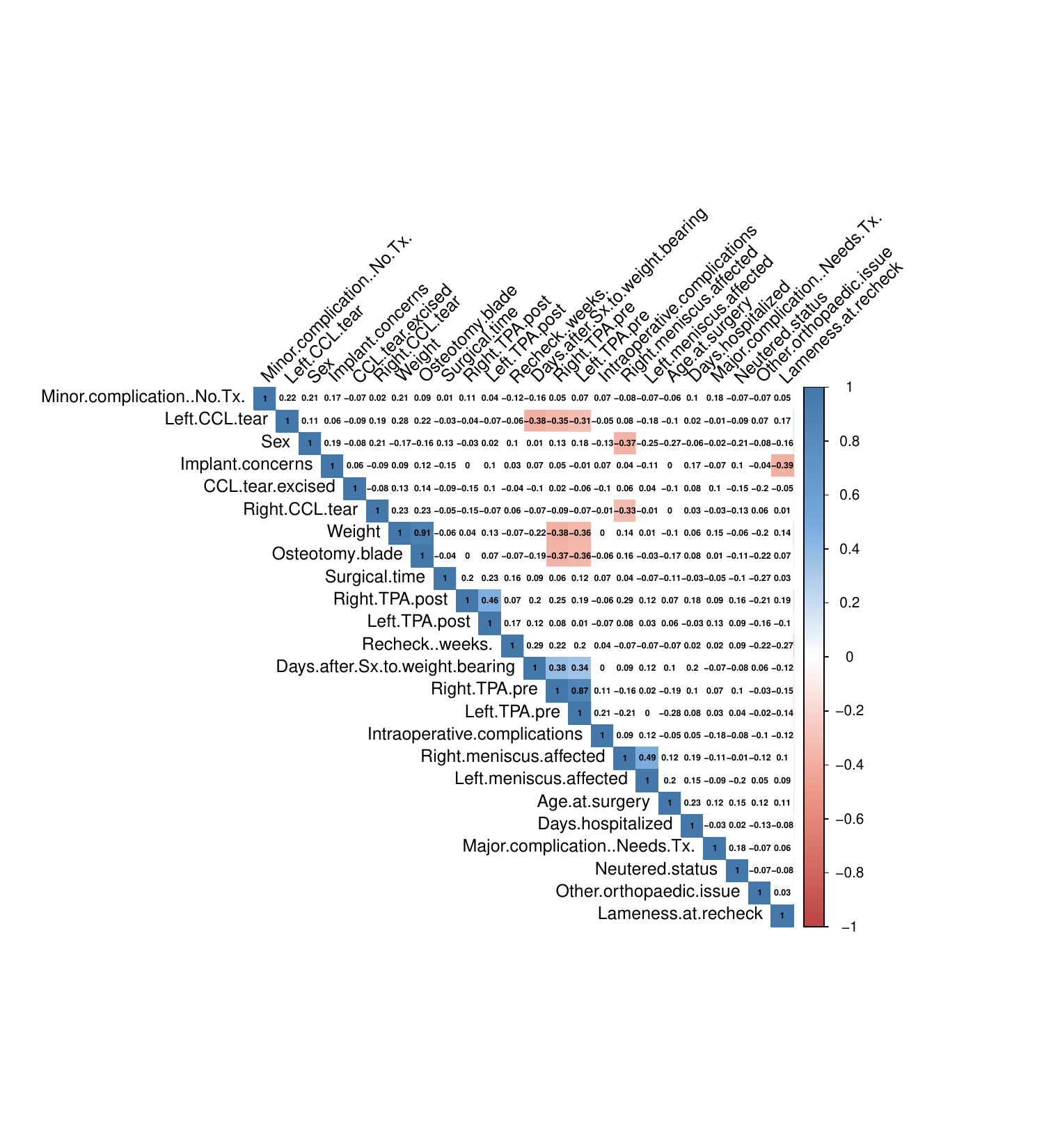
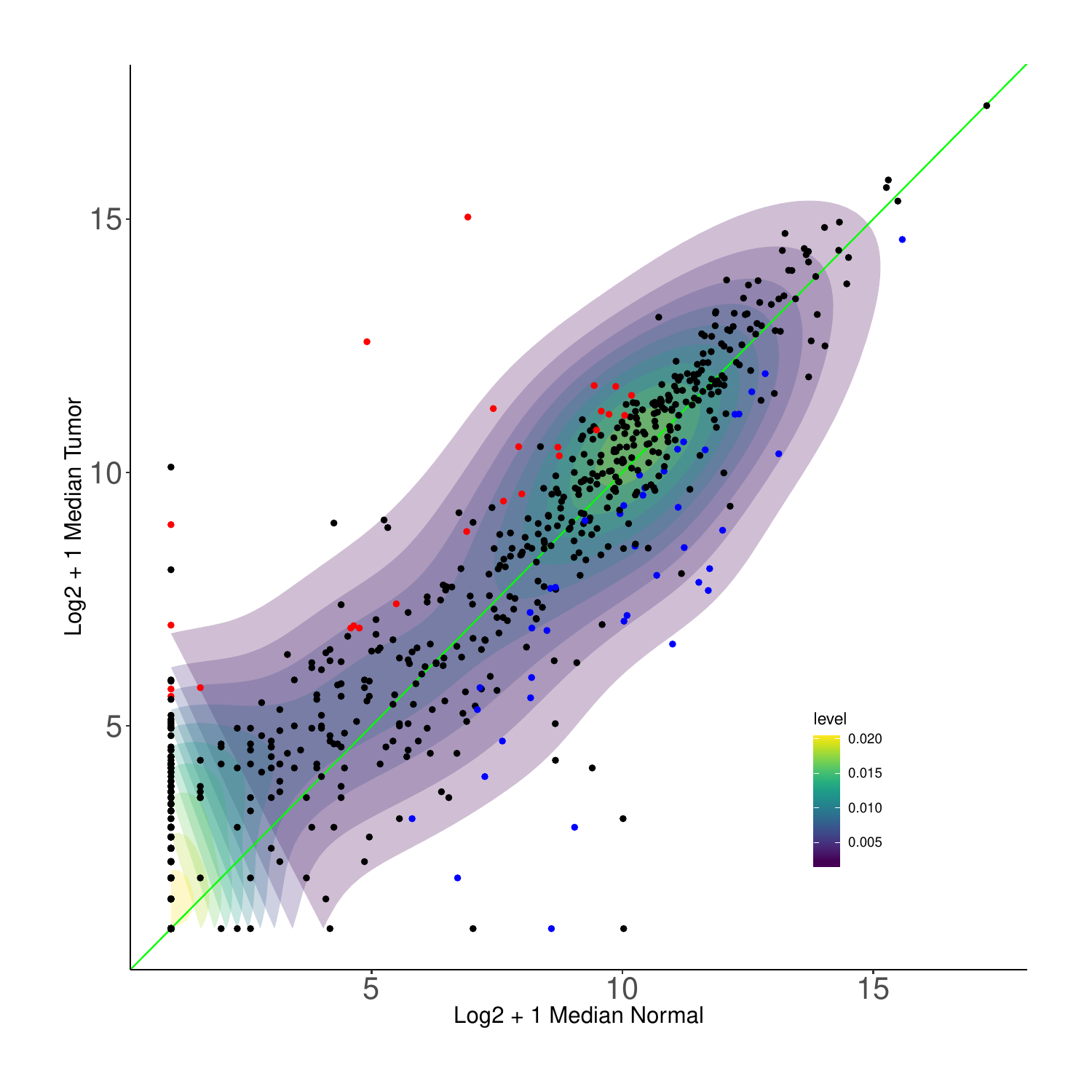
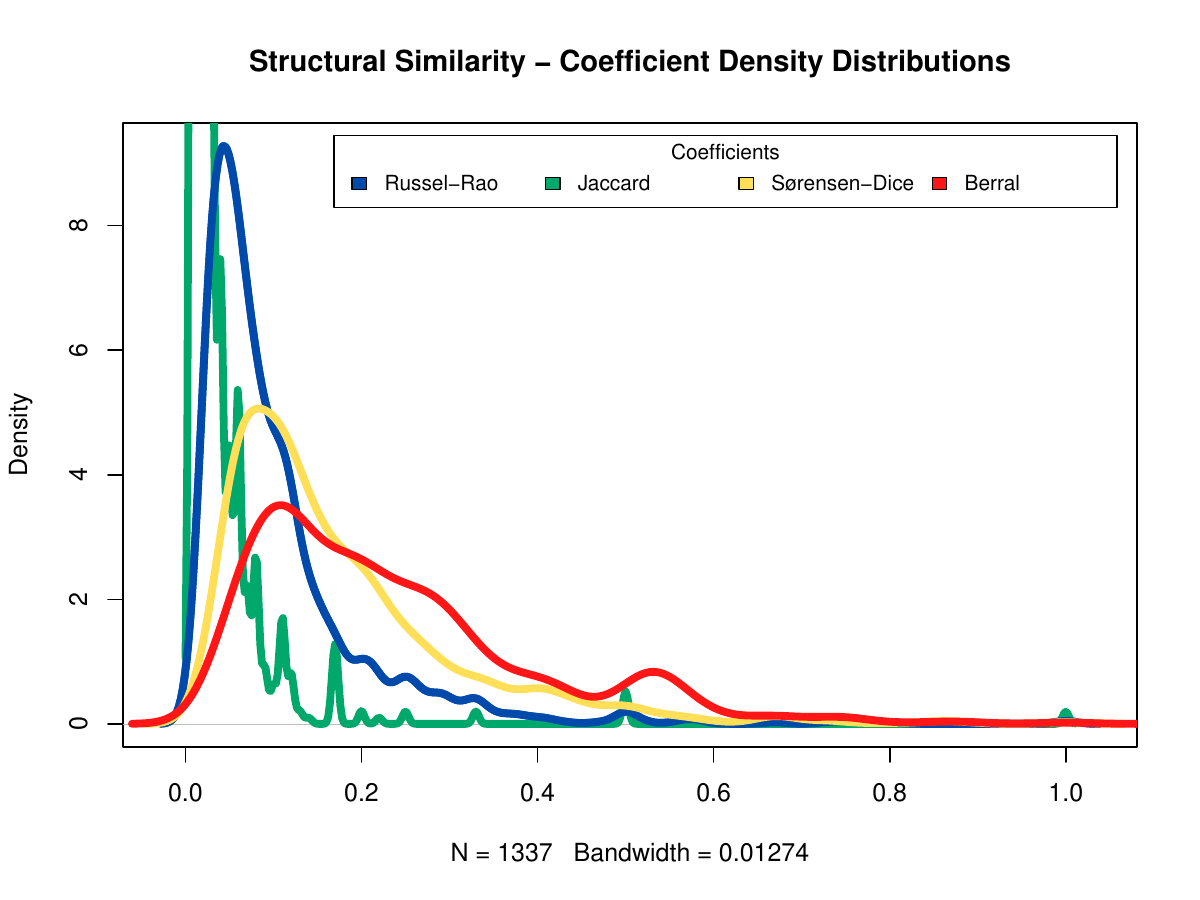
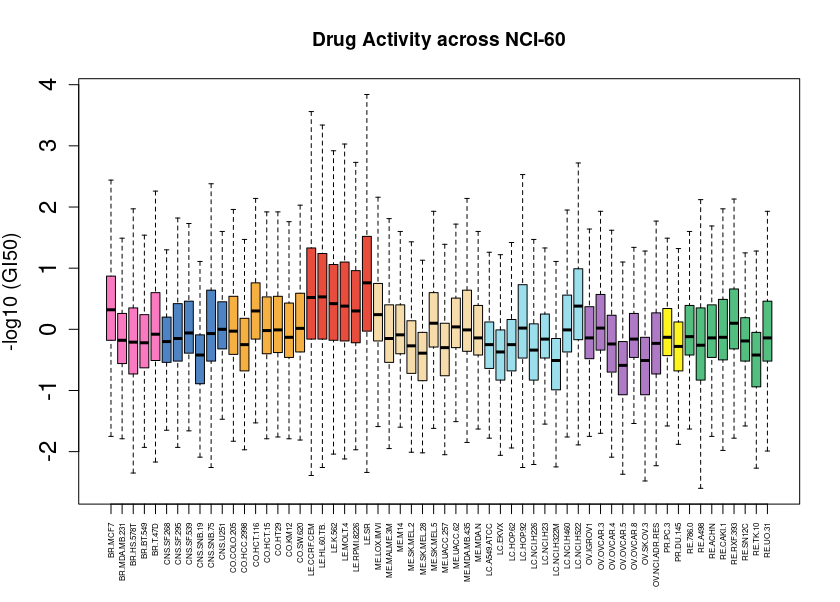
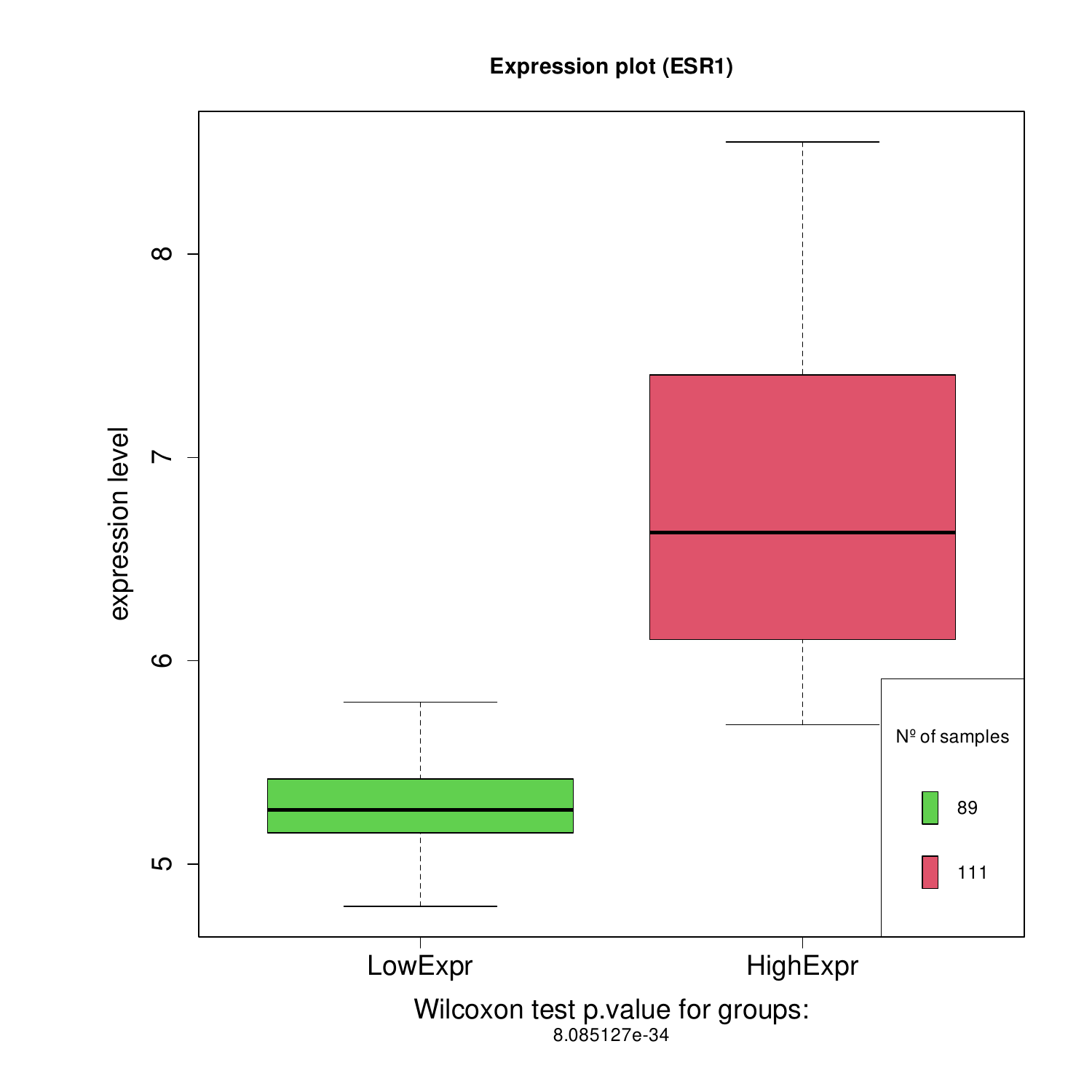
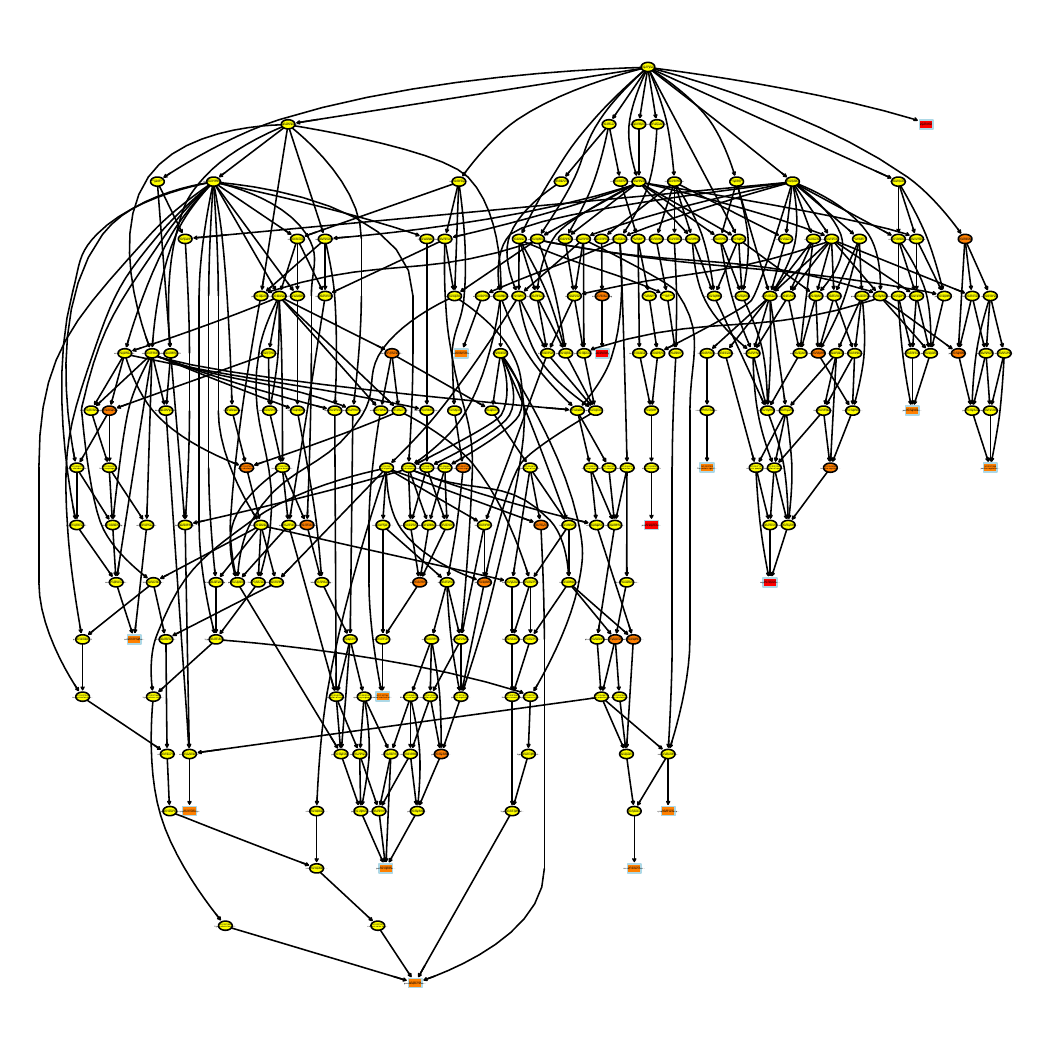
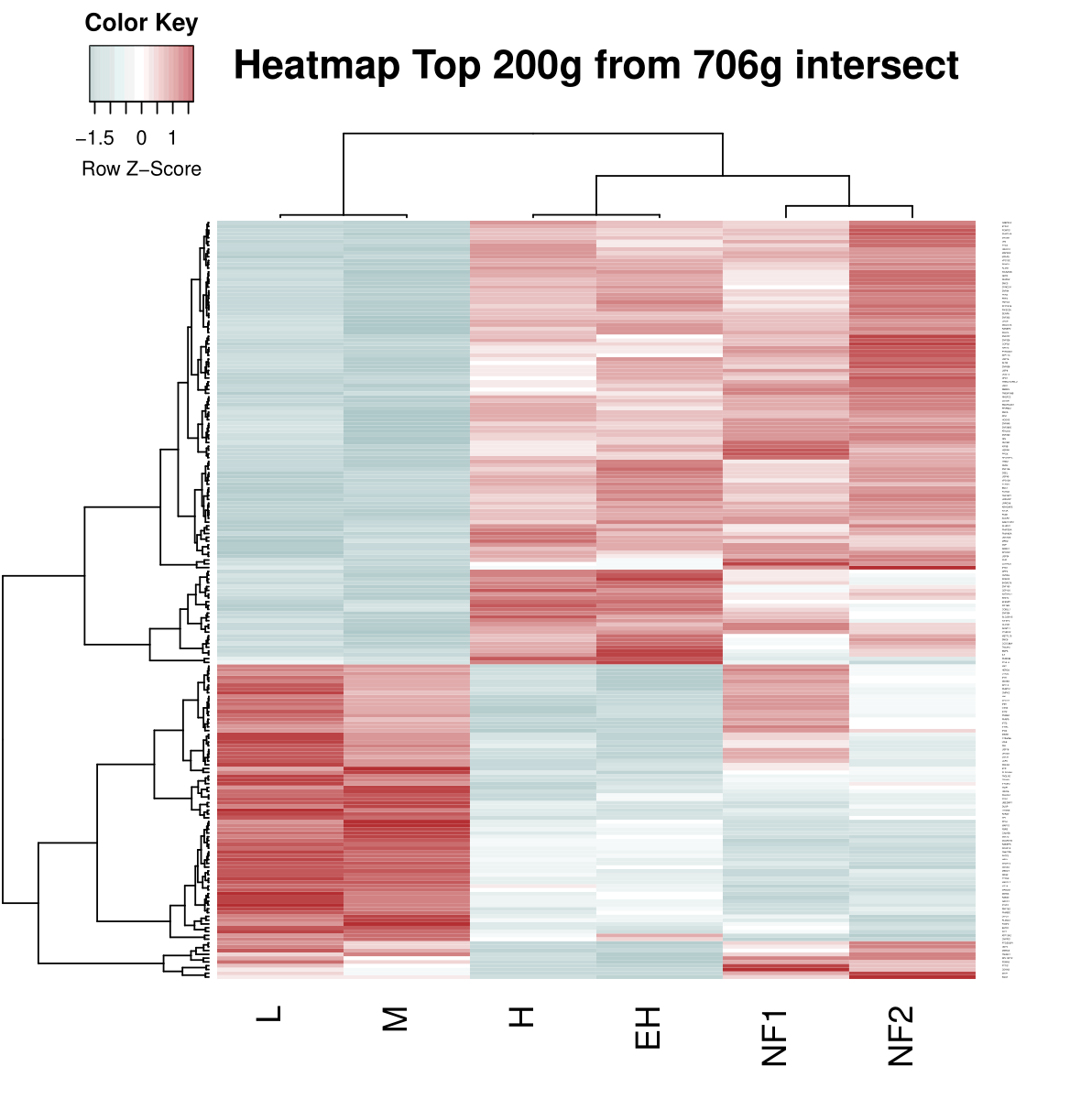
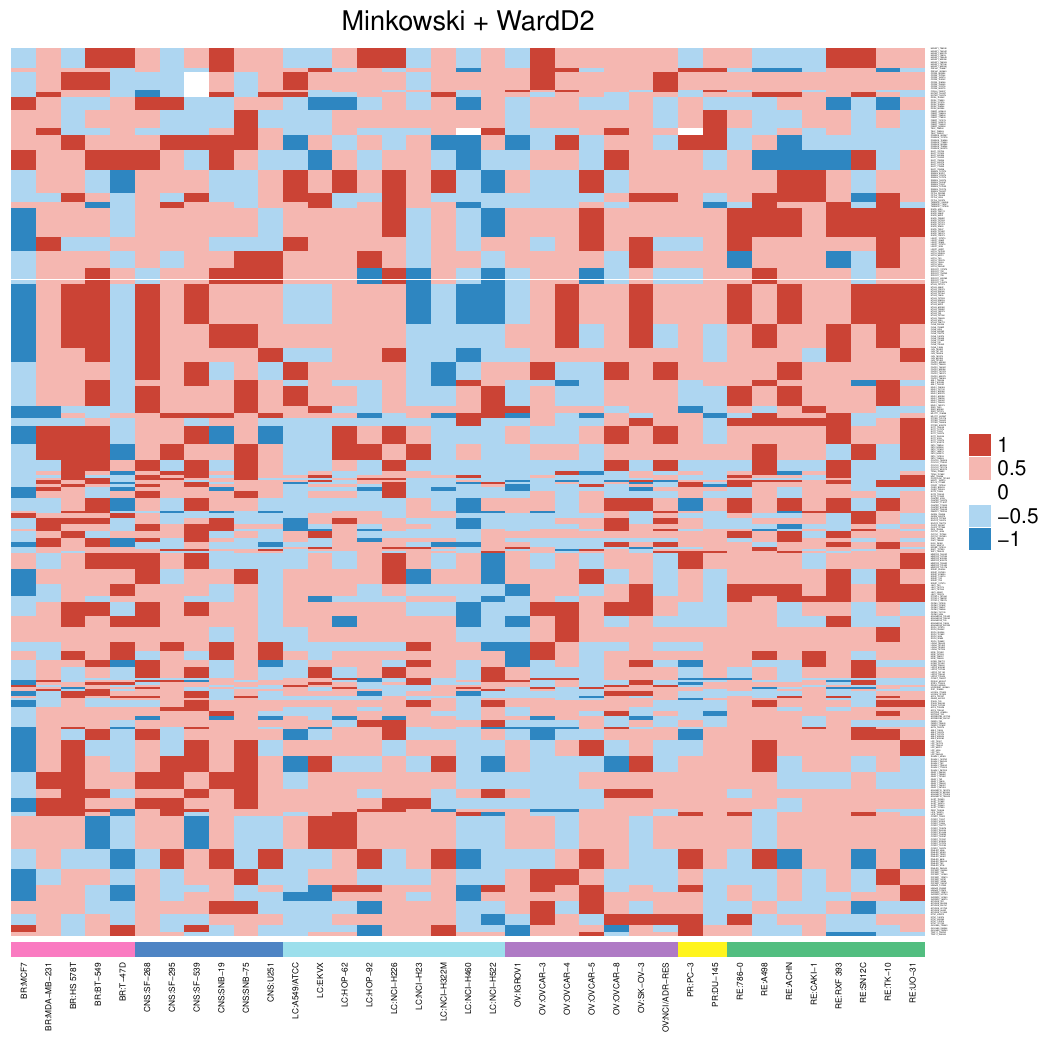
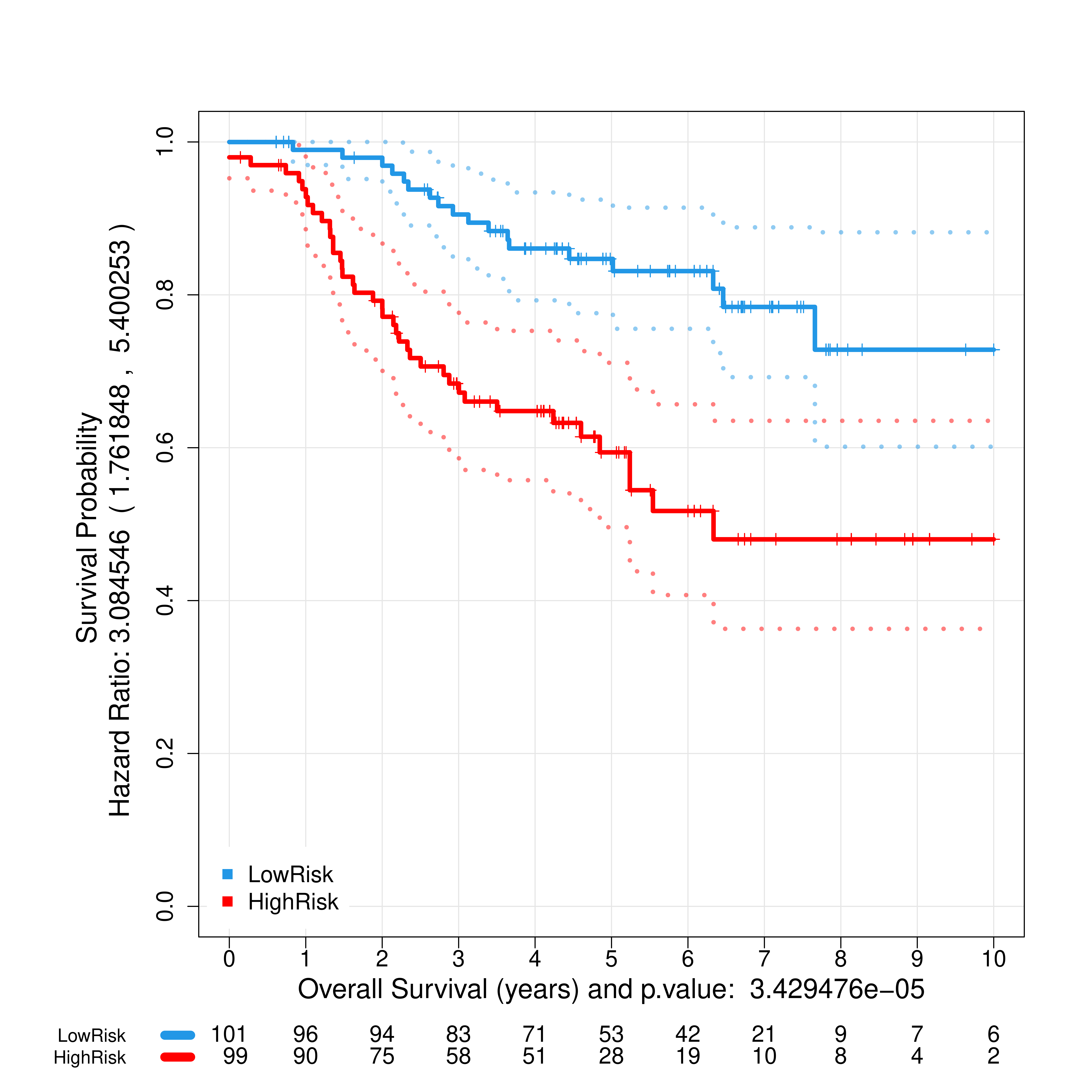
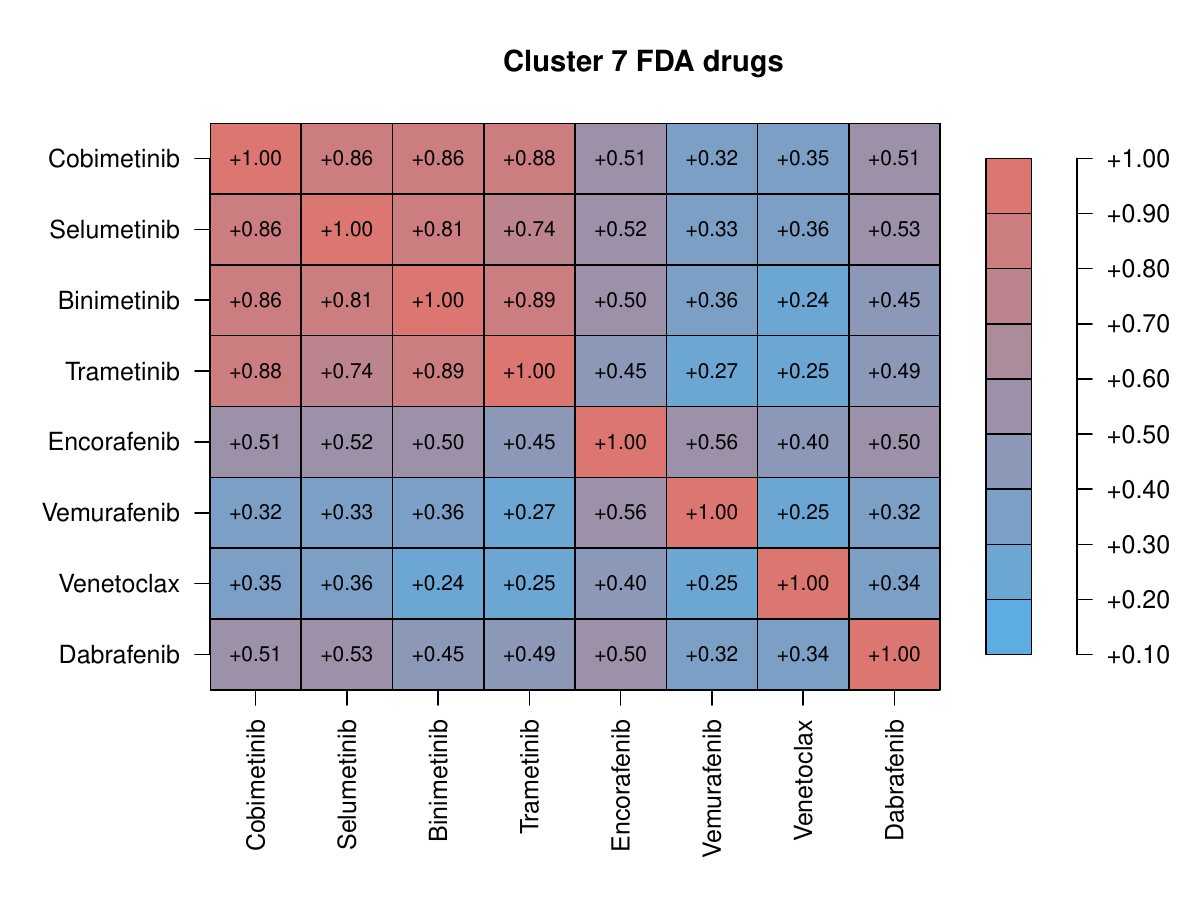
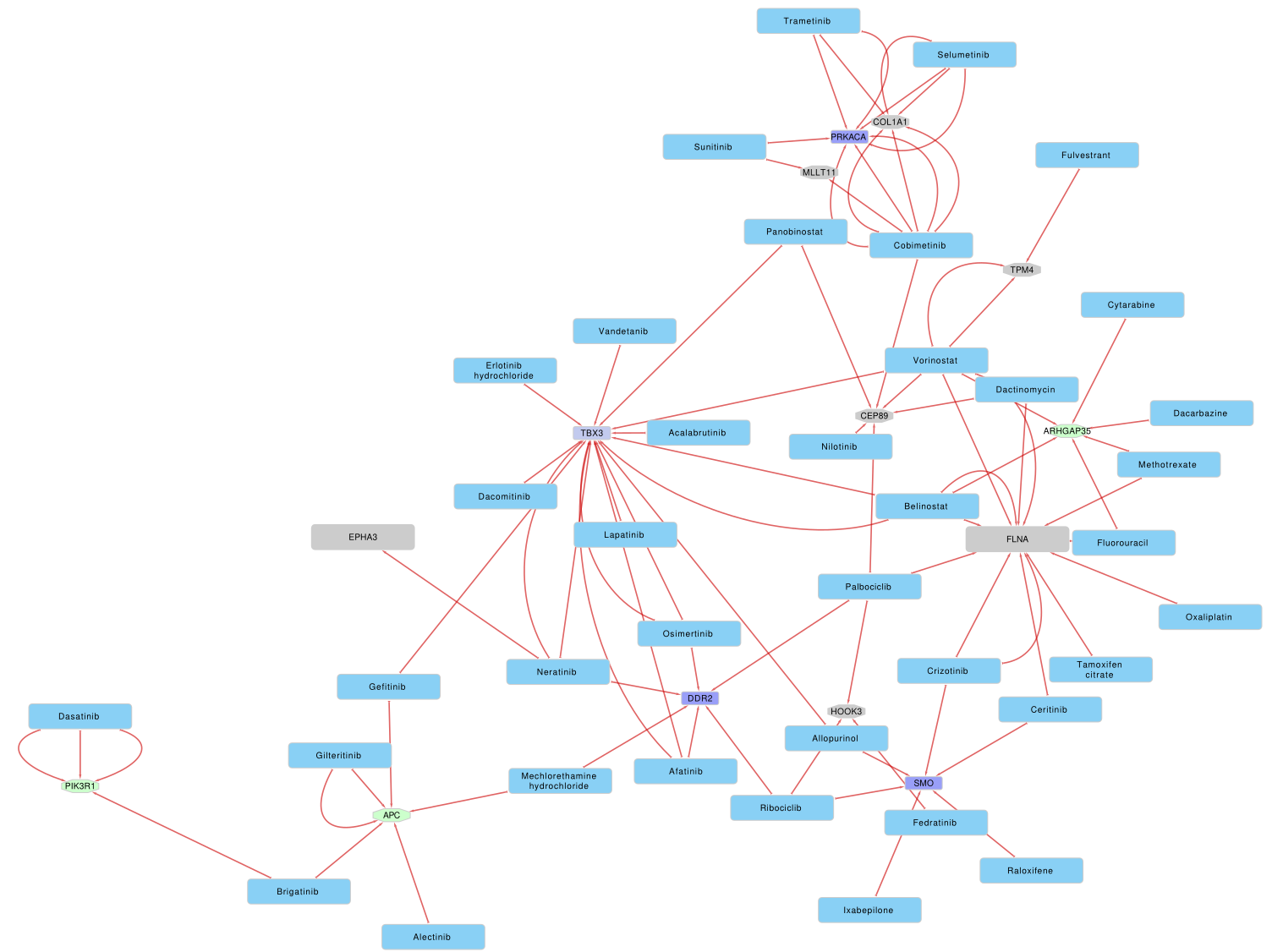
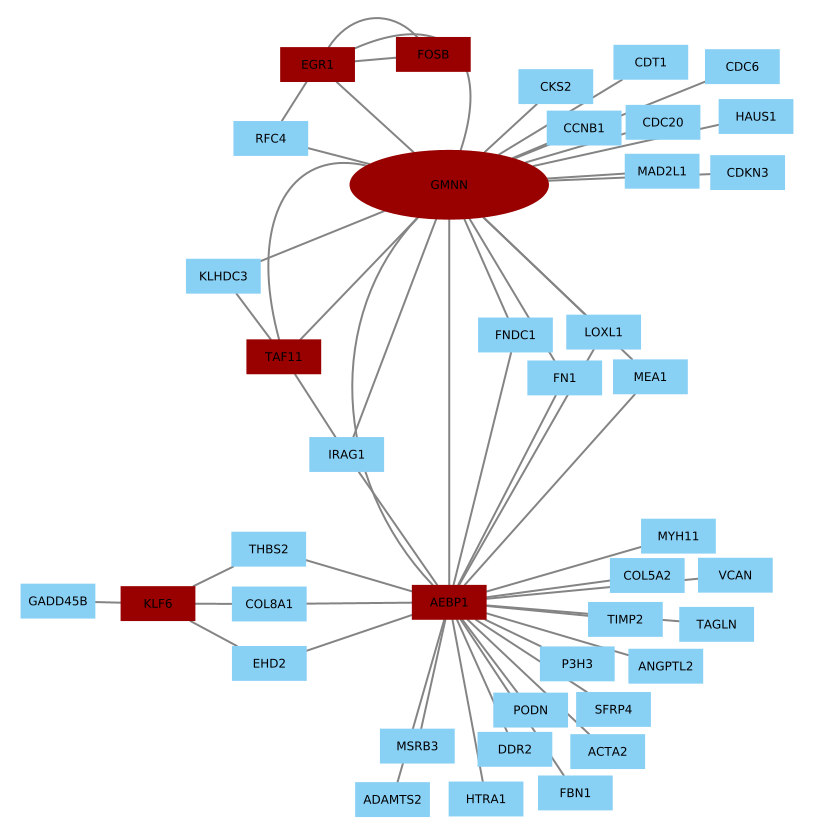
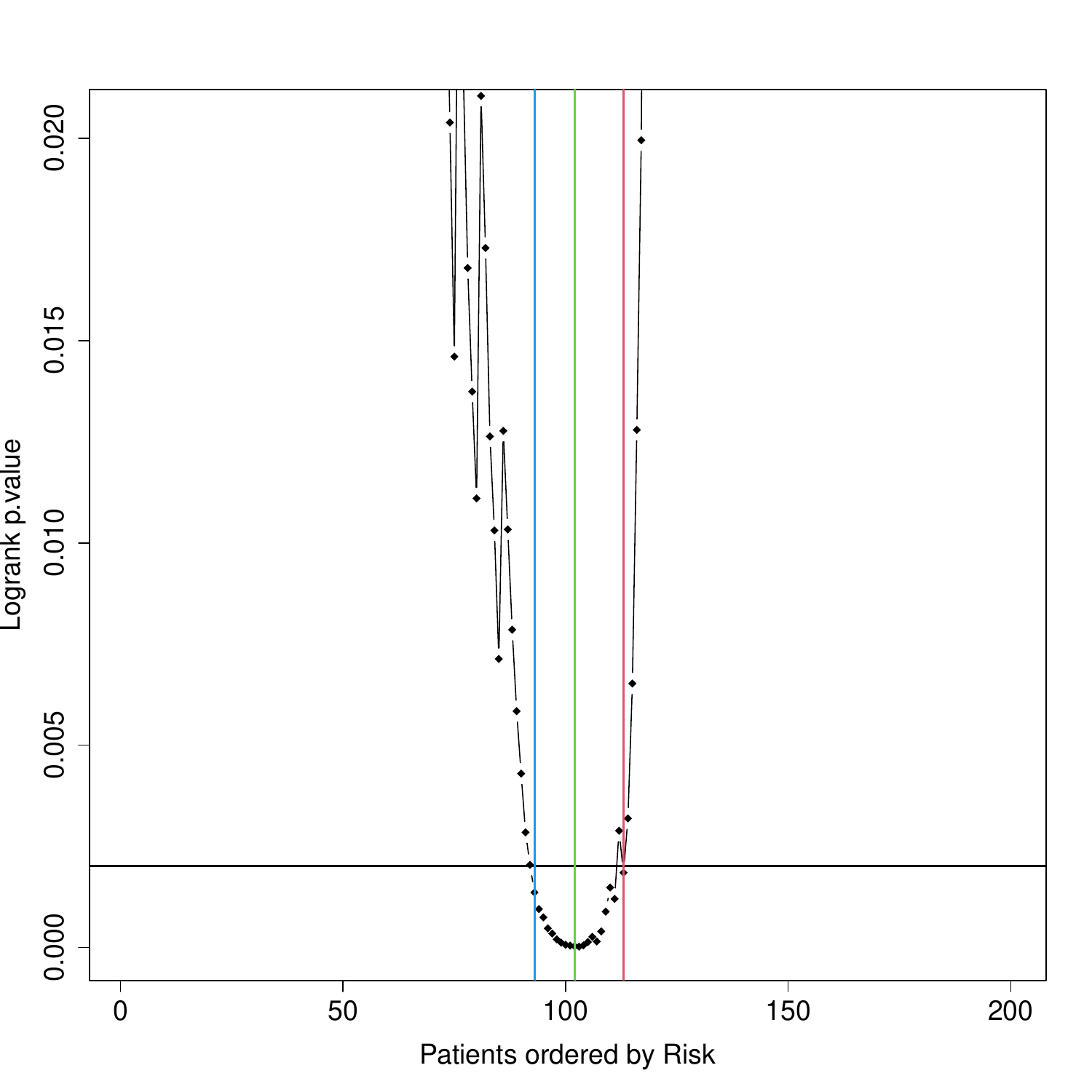
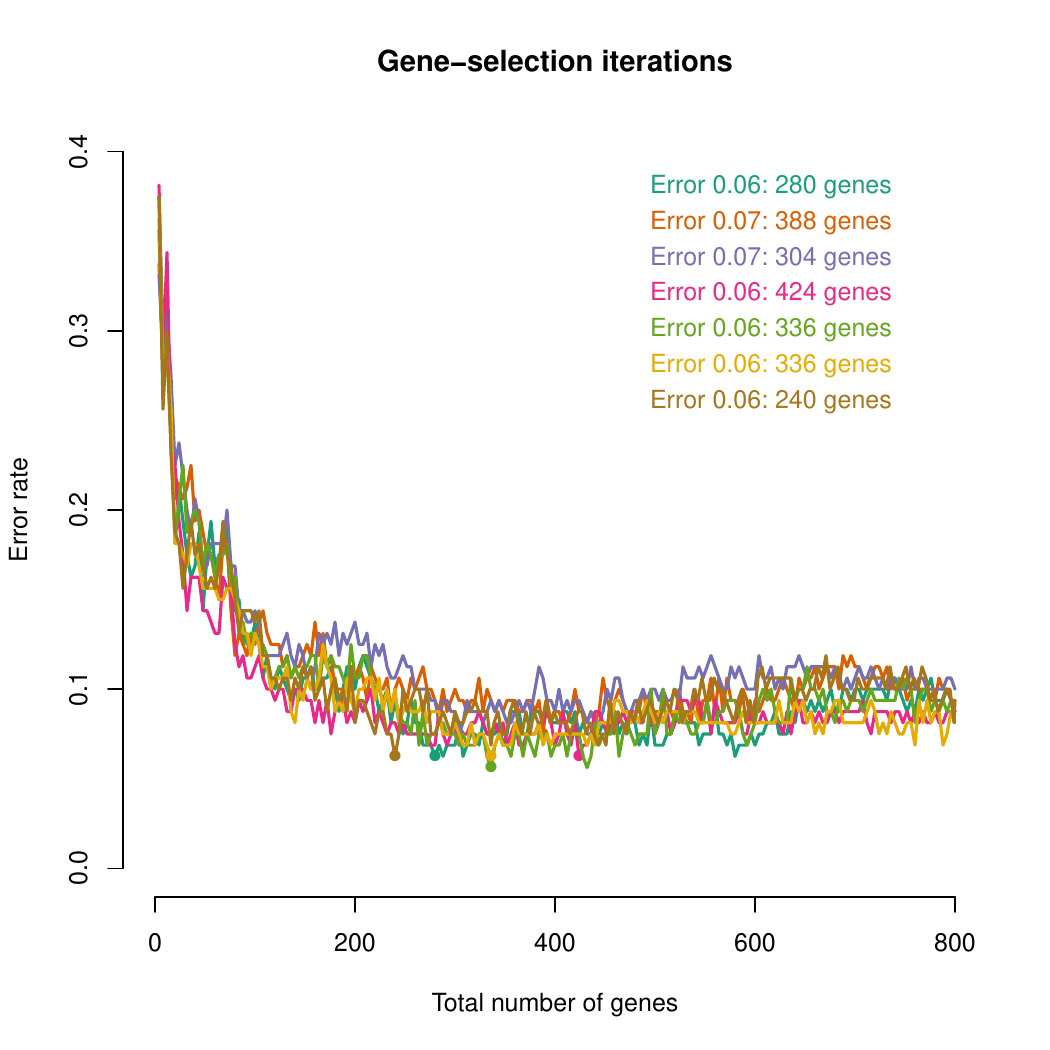
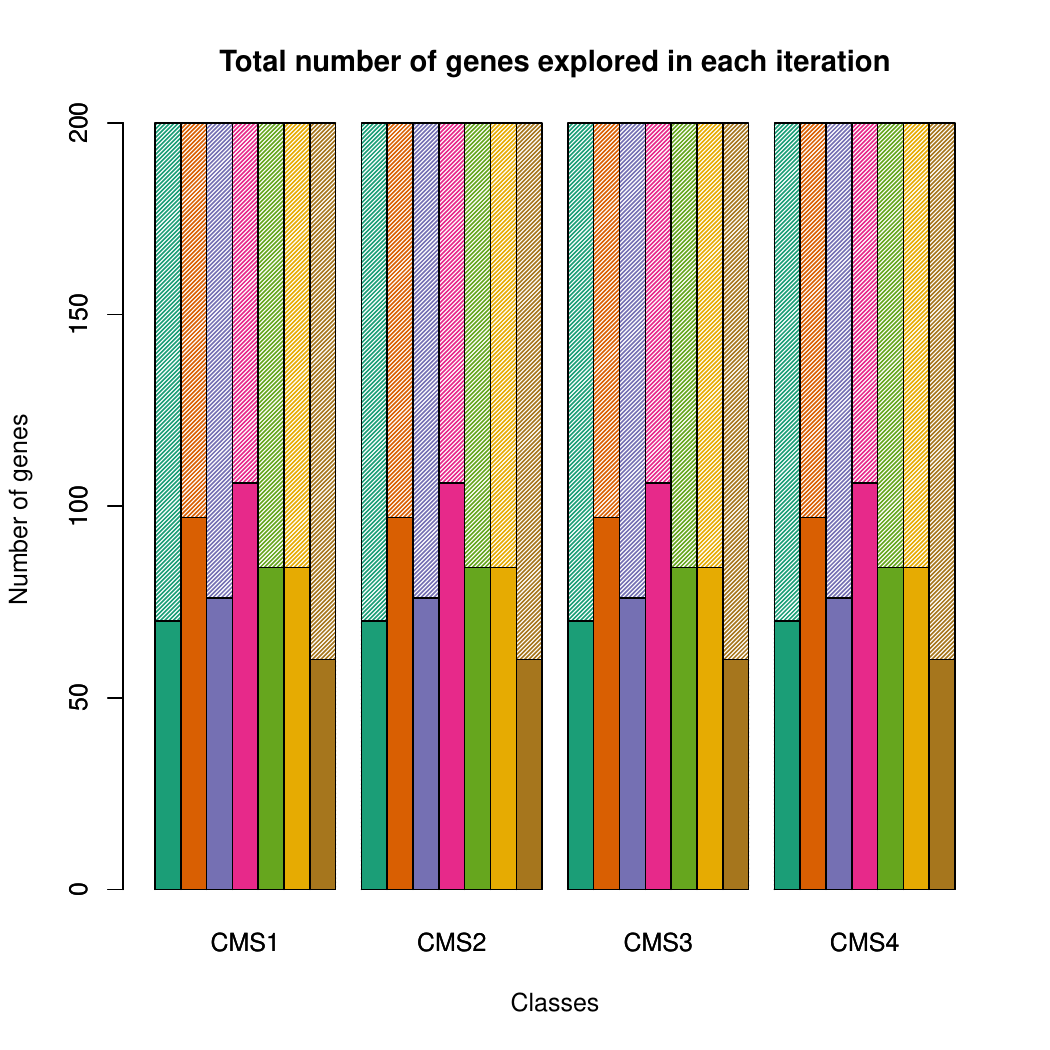
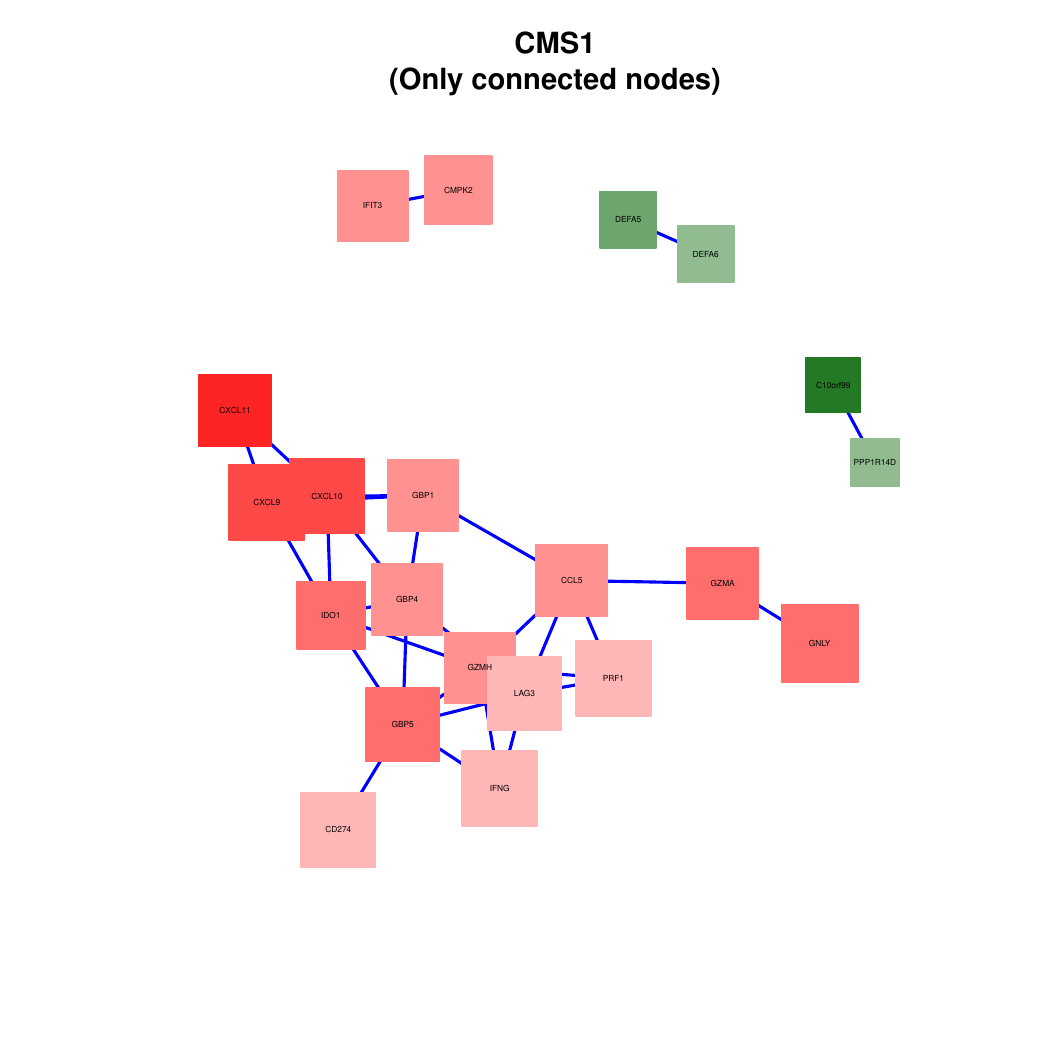
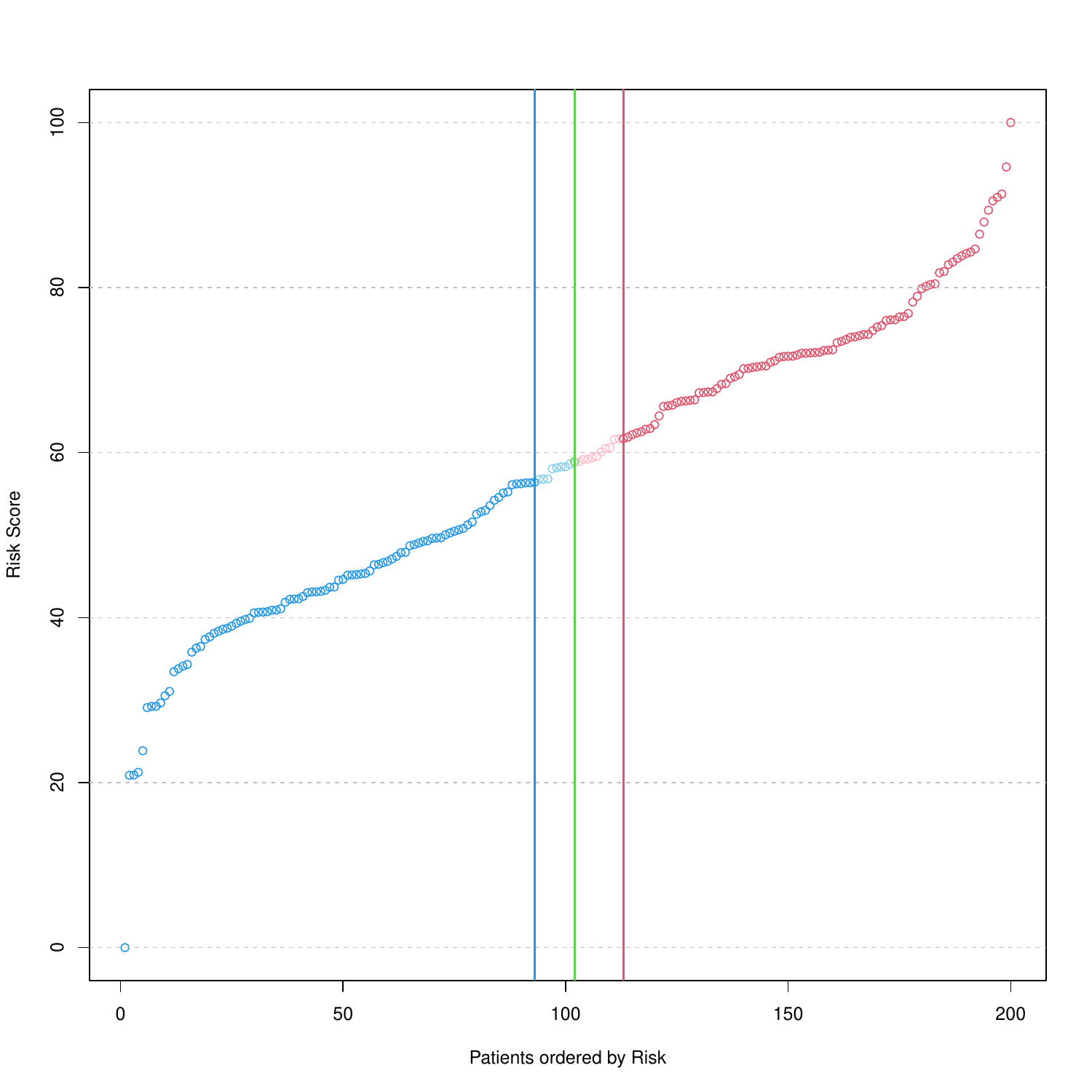
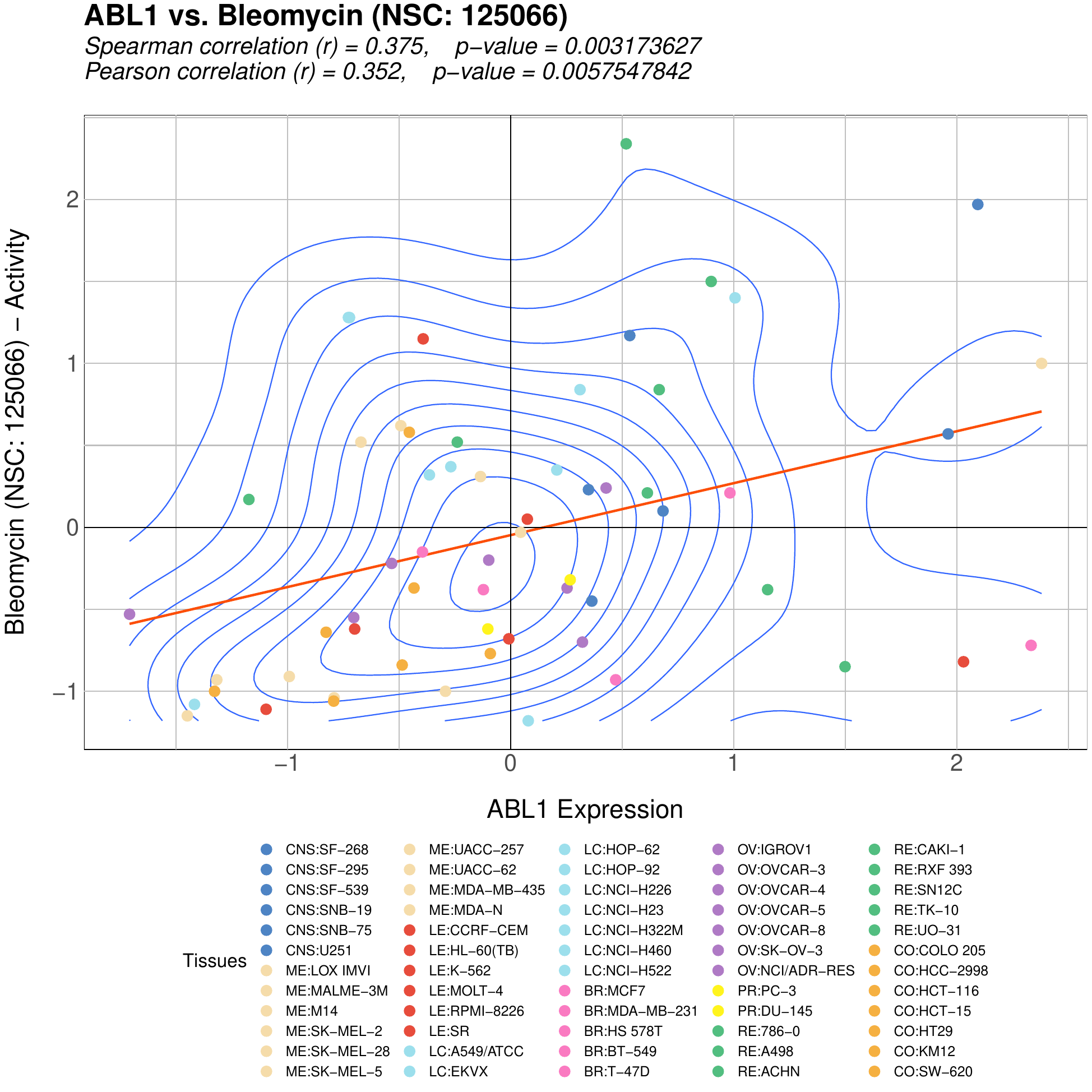
The images below show some of the results of my daily basis work. This process includes data exploration, pattern identification, network analysis or prediction, informed decision analysis and functional exploration of the results.